
|
Al sinds 2010 blijft de snelheid van een processor hangen op 3GHz
1 Bijlage(n)
Kijk. De snelheidslimiet van de processor lijkt bereikt.
3GHzVoor 2010 was er verbetering op een logaritmische schaal. BRON |
Het is al lang de vraag waarom de kloksnelheid van microprocessoren nog zou moeten verhogen.Voor het verhogen van de verwerkingssnelheid is het verhogen van de kloksnelheid al sedert de eerste pentiums 20 jaar geleden niet meer de voornaamste factor.
Veel belangrijker bleek het "multi-core" concept (algemeen geworden,tot in de processors in uw smart-phoontje toe),en de gesofistikeerde threading en multitasking concepten die in het "silicon" gebakken worden. Het verbruik,veel belangrijker in het licht van de achterophollende batterijtechnologie, is wel direct gerelateerd aan de gebruikte spanningen en kloksnelheden.....De overgrote meerderheid van microprocessoren dient nu voor mobiele toepassingen en dat dikteert dus de markt....Niet de "brute verwerkingseenheden" voor gamers en supercomputers.... De fabrikanten zijn dus eerder aan het "balanceren" van mogelijkheden dan aan het "opdrijven" van prestaties. Zelfs in zeer gesofistikeerde wapensystemen zijn de prestaties van de microprocessoren ongetwijfeld al meer dan een decennium niet het voornaamste probleem.Eerder gaat het er om al die gesofistikeerde hardware aaneen te breien met goedgeschreven software en dit voldoende TRAAG te laten werken opdat Homo Sapiens nog overweg kan met zijn eigen creaturen..... |
Zoals Kelt zei, voor de rest is de snelheid van de processoren voor een pc voor huis tuin en keukengebruik allang goed genoeg.
|
De vooruitgang even in beeld: (voor autonome autos bvb, beelden per sec)
 http://wccftech.com/nvidia-pascal-gpu-drive-px-2/ Meer specs: https://vrworld.com/2016/04/13/nvidi...ed-drive-px-2/ |
Nog maar eens een Nr 10 topic in wetenschap & technologie, vol posts van zichzelf met ettelijke links die hij zelf niet begrijpt...
Processors @ 4GHz & 5GHz zijn zelfs domweg te koop. Tot zover de "limiet"... |
Citaat:
ook de grafiek loopt maar tot ergens 2013? Citaat:
Citaat:
Citaat:
|
Een paar jaar geleden 'ergens' 'iets' gelezen (kan in EOS zijn geweest, maar ik weet het niet meer zeker) over een revolutie in processortechnologie, dataopslag en de verwerking die de snelheid factor 10 of meer zou verhogen. Gebruik van organisch materiaal of zo iets. Helaas daarna nooit meer iets van gehoord.
|
Citaat:
|
Citaat:
Researchers tell us that the human eyes receive about 20 Mbps of data through the optic nerves. If we generously add another 192 kbps for perceptual audio coding, we can justify 20.2 Mbps for streaming data applications. We could support 50 immersive video experiences with a single 1 Gbps 5G terminal. This hardly seems reasonable or useful.Het menselijke oog streamt data aan 20 Mbps. De audio die door het oor passeert streamt aan 192 kbps. ==> een verbinding van 20,2 Mbps is voldoende om het menselijke oog en oor na te bootsen met een videocamera. |
Citaat:
Citaat:
Citaat:
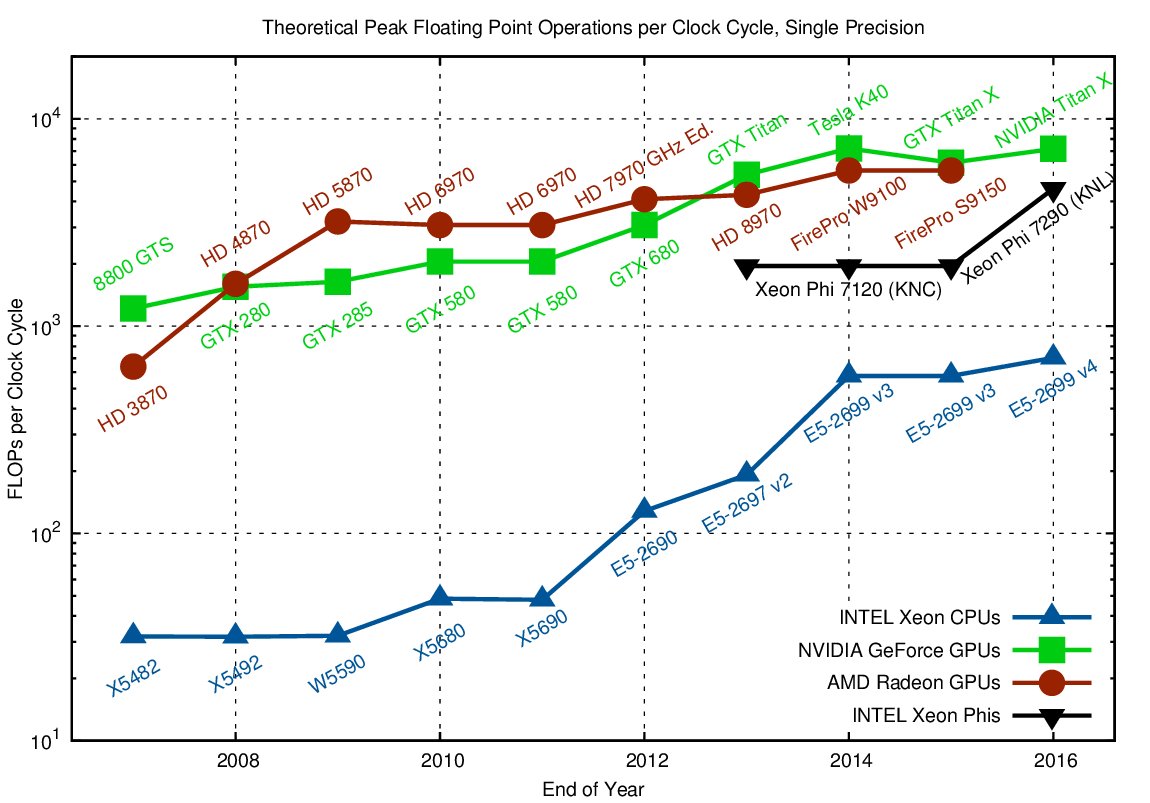
Neem eens de grafiek van FLOPS tussen 2010-2016... |
Citaat:
|
Als je een CPU of GPU koopt enkel op basis van clock snelheid ga je berooid thuiskomen.
Een titan X draait rond de 1 Ghz, maar is twee keer zo snel als een AMD fury X 1 ghz.... De architectuur zegt meer als de clocksnelheid in vele gevallen. |
Citaat:
Geen enkel fysisch principe of wetmatigheid vormt de grondslag ervan. Het is een observatie van Moore uit de jaren '60. |
Citaat:
Geschiedenis |
Citaat:
Nodes, Sockets, Cores and FLOPS In the past, a chassis contained a single node.Laat ons een paar termen definiëren meldt de auteur:
|
Citaat:
|
Ik ken een ingenieur die de machines ontwerpt die nieuwe chips moeten etsen. Er is een limiet bereikt. Diep UV kan niet fijner meer etsen.
Voor de volgende grote stap zou men naar Röntgen moeten gaan. Maar dan loopt men aan tegen het feit dat de breedte van het geëtste spoor ongeveer even breed is dan 1 "transistormolecule". Moore kon deze graad van "fijnheid" niet voorspellen in de jaren 70. Zie maar hoe de meeste voorspellingen in de loop der jaren gewoon mis bleken. |
Citaat:
And as for processor frequency: zoals eerder ook al gezegd zijn de grote chips-bakkers al enkele jaren geleden afgestapt van het principe dat ze telkens hogere kloksnelheden moesten krijgen. AMD heeft dat besef weliswaar wat later gehad, maar ook zij zijn uiteindelijk tot dezelfde conclusie gekomen :-D. Issue voor hogere kloksnelheden is trouwens niet de verderzetting van Moore, wel de power-consumption die daarmee gepaard gaat. |
1 Bijlage(n)
Citaat:
In general, a core can do a certain number of FLOPs or FLoating-point OPerations every time its internal clock ticks. These clock ticks are called cycles and measured in Hertz (Hz). Most microprocessors today can do four (4) FLOPs per clock cycle, that is, 4 FLOPs per Hz. Thus, depending upon the Hz frequency of the processor’s internal clock, the floating point operations per second or FLOPS can be calculated. The internal clock speed of the core is known. It’s that GHz rating typical of today’s processor. For example, a 2.5-GHz processor ticks 2.5 billion times per second (Giga ~ billion). Therefore, a 2.5-GHz processor ticking 2.5 billion times per second and capable of performing 4 FLOPs each tick is rated with a theoretical performance of 10 billion FLOPs per second or 10 GFLOPS. Citaat:
|
De snelheid van zogenaamde supercomputers wordt uitgedrukt in FLOPS.
Hoe de architectuur van dergelijke supercomputers eruit ziet? De snelste supercomputer ter wereld staat momenteel in China, heeft een score van 93 PFLOPS, en heeft een totaal van 10.649.600 cores over het hele systeem. Op het systeem kan code geparallelliseerd uitgevoerd worden. BRON |
1 Bijlage(n)
Citaat:
Met meerdere cores op één processor mogelijk. Bijvoorbeeld:
Fabrikanten van microprocessoren verkopen processoren. Met bijhorende adjectieven. Door meerdere cores te combineren verhoogt de FLOPS score, maar niet de kloksnelheid. (fig.) |
1 Bijlage(n)
Nog enkele vragen.
Waarom de FLOPS van de CPU verhogen door meerdere cores te installeren? En wat met de software als er meerdere cores zijn? (fig.: Quad-core CPU) |
Citaat:
Als je (tegenwoordig enorme-) brokken "kode" kunt verdelen over meerdere processor-kernen,hoe ver kun je daarin gaan zonder dat de software die in de microprocessor zelf "ingebakken" is,en die de planning moet doen, zelf te ingewikkeld moet worden omdat,uiteraard,brokken software van het gebruikersprogramma die apart op verschillende cores draaien riskeren gegevens van elkaar nodig te hebben en dan maar allemaal staan wachten op elkaar.(ik stel het vereenvoudigd voor omdat mijn begrip van de materie ook niet diep is,ben al blij wat met een arduinootje te kunnen spelen :roll: ) Ik vrees dat het al meer voorkomt dan we weten,immense verwerkingssnelheid die verloren gaat omdat laag na laag software volautomatisch eventjes "in wacht" staat op andere stukken kode die op een andere core bezig zijn.... |
Citaat:
Citaat:
Hier te vinden Citaat:
Waarom vraag je dat als je het altijd ergens kunt vinden? Is een forum een vragenspelletje ?  |
Citaat:
|
 Citaat:
|
-
|
Citaat:
https://www.extremetech.com/extreme/...f-modern-chips |
Citaat:
Het vorige pivot-jaar in HPC, volgens de auteur, was 1994. Het jaar van de bouw van de eerste "cluster" van 16 machines, verbonden via LAN, die applicaties liet draaien alsof ze op één machine draaiden. De zogenaamde Beowulf. Hier vind je een handleiding om een Beowulf cluster te bouwen. What is a Cluster? |
1 Bijlage(n)
De snelheid van zogenaamde supercomputers wordt uitgedrukt in FLOPS.
Hoe de architectuur van dergelijke supercomputers eruit ziet? De snelste supercomputer ter wereld staat momenteel in China, heeft een score van 93 PFLOPS, en heeft een totaal van 10.649.600 cores over het hele systeem. Op het systeem kan code geparallelliseerd uitgevoerd worden. BRON Hieronder een zogenaamde TPU pod van Google. Het apparaat bestaat uit 64 TPUs van de tweede generatie. 180 TFLOPS x 64 = 11,5 PFLOPS (aanklikken om te vergroten) |
De TPU wordt omschreven als zijnde een ASIC, een applicatie-specifieke geïntegreerde schakeling.
|
Bitcoins werden eerst gedolven met CPUs.
Vervolgens met GPUs. Sinds 2013 gebeurt dat met ASICs. |
Microsoft noemt z'n extra processor de "HPU".
Movidius bouwt een processor voor VR/AR, de "VPU".
3 jan 2016 To boil it down, Movidius explained the point of the VPU by noting that it’s no longer sufficient to render a complex scene as a GPU does; the device must understand it. That’s just a different beast. Company representatives told Tom’s Hardware in a briefing that cramming that much performance into a low-power SoC was not previously possible and required offloading complex processing to servers in the cloud. The continuing advance of technology, coupled with specialized processors like the Myriad 2 VPU, are allowing these calculations to be done on device, eliminating network latency and enabling new experiences.SoC = System on a chip A system on a chip or system on chip (SoC or SOC) is an integrated circuit (also known as an "IC" or "chip") that integrates all components of a computer or other electronic systems. It may contain digital, analog, mixed-signal, and often radio-frequency functions—all on a single substrate. SoCs are very common in the mobile computing market because of their low power-consumption. BRONMovidius werd in september 2016 ingepalmd door Intel. |
Om nog eens terug te komen op de kloksnelheid, hieronder een grappig artikel uit 2000. Toen zag Intel nog veel heil in hoge kloksnelheden. Enkele jaren later hebben ze dat plan moeten laten varen.
https://www.geek.com/chips/intel-pre...y-2011-564808/ Tot ongeveer 2005 zette men fors in op meer MHz, daarna is de winst uit andere architecturale zaken gekomen. |
Citaat:
intel is predicting that its microprocessors will hit 10ghz by the year 2011.:lol: |
Citaat:
Dit wil zeggen. Alle code bestaat uit 0 en 1. Wat van het volgende denken? Vers van de Zwitserse pers: Quantum Breakthrough: Researchers Successfully Simulated a 45-Qubit Quantum Circuit Modern day computers use digital computing which requires all data to be encoded in binary digits (bits). On the other hand, Benioff’s quantum computer or Quantum Turing machine is a theoretical model which requires the use of quantum bits in its computation. Unlike the regular bit which can only be 1 or 0, a quantum bit or qubit can be in superposition. This is a state which allows it to hold more information. A quantum bit can contain a combination of 2 or more bits(1 or 0) by using superdense coding. The superposition state of qubits will allow a quantum computer to work on a million computations at once. A regular desktop computer can only work on one. As a result, modern researchers like Häner and Steiger are pushing the limits of our generation’s most advanced supercomputers to develop future quantum computers. Using the fastest computing machines help these experts discover quantum computing breakthroughs. These will be useful in revolutionizing material science, machine learning, quantum chemistry, and cryptography. (...)De twee Zwitsers bereikten een gemiddelde van 0,428 PFLOPS. Met hun simulatie van een 45 qubit circuit. Wat bij de auteurs van het artikel de volgende vragen uitlokt: Is humanity really at the edge of achieving quantum supremacy? |
1 Bijlage(n)
Verwijzend naar post 30 uit deze discussie.
In verband met het via deep learning trainen van NLP systemen voor de Chinese taal. De enorme rekenkracht die hiervoor nodig is. Een wetenschapper bij Baidu aan het woord: BRON Tientallen exaflops om deep speech te trainen. “As with other deep neural networks, our system gets more and more accurate as it is trained on larger and larger datasets. [Baidu] researchers have been working hard to find large datasets from which our model can learn all the nuances and complexities of spoken Chinese, which is a very diverse language with many dialects and local accents. As we amass these datasets, we encounter interesting systems problems as we try to scale the training of our system. |
Toepasselijk heeft men het nu,de eerste week van het jaar 18,over een aanzienlijk probleem met dat "cachen" en "voorspellen" dat reeds in de microcode "ingebakken" zit van moderne processoren.
Dit is eigenlijk geen "ontwerpfout",het is een denkwijze die nog stamt uit de tijd (en dat is eigenlijk nog niet zo lang geleden)dat het overgrote deel van de microprocessors zat in apparatuur die niet-,of slechts af en toe,aan een vorm van netwerk,om nog niet te spreken van het internet ,hingen.... Ik begrijp het probleem niet zo goed,(geen kodeklopper zijnde),maar NU het merendeel van betreffende apparatuur zeer lange tijd aan het net hangt beseft men blijkbaar dat anderen kunnen "snuffelen" en uit dat "voorspellend" gedrag van een processor (waarbij een cache-geheugen reeds wordt geladen met instructies die MOGELIJK zouden kunnen nodig zijn) genoeg informatie halen om de datastroom te gissen.......en daar eventueel iets leuks mee te doen.... Hoe men dat "probleem" met de ingebakken microkode afdoende zou oplossen met een upgrade aan het Operating Systeem is me al helemaal niet duidelijk,mogelijk zullen er implicaties zijn met de snelheid van het toestel.(want dat "cachen" en "voorspellen" en zo was juist om snelheid gedaan). |
Wie gaat straks nog uitvinden en ondernemen?
Zoals te verwachten zijn in de VS verschillende "class action suites" aan het opstarten.Advokaten-schorremorrie en "benadeelde" klanten vinden dat Intel geld op tafel moet leggen naar aanleiding van die "bugs".
https://arstechnica.com/gadgets/2018...n-and-spectre/ Persoonlijk geloof ik niet dat de aanklagers dit gaan winnen gezien er helemaal geen sprake is van een "fout" of zelfs maar een "bug" en zeker niet van kwade wil... Processors hebben zich de laatste paar decennia ontwikkeld volgens een structuur,een systeem,die vanuit veiligheidsoverwegingen wat verouderd lijken voor de huidige genetwerkte maatschappij. Veranderingen zijn soms pijnlijk... Niettemin is gans die zever met rechtszaken (in de VS waarlijk een pest,al is het maar omdat er een immense meute nitwitten van moet leven) dodelijk voor kleinere technologie-bedrijven (die bijna zeker wel ergens een patent-claim aan de broek kunnen krijgen van zodra ze ergens een gat in boren en er een bout en moer aan bevestigen,of zodra ze iets kleurigs op een beeldscherm programmeren),en voor grote bedrijven een aanhoudende en irritante kost..... Nu weer omdat mogelijk de snelheid van de intel-processoren (waar ze altijd mee aangeprezen werden) wat kan verminderen wegens beveiligingsmaatregelen.....o jeetje....wat een ramp....ik wil onmiddelijk 10 miljoen dollar (waarvan 1 miljoen voor mijn advokaat) |
Citaat:
Er is momenteel geen enkele desktop cpu beschikbaar die de Spectre of de Meltdown kwetsbaarheden ingebakken heeft. |
| Alle tijden zijn GMT +1. Het is nu 01:50. |
Forumsoftware: vBulletin®
Copyright ©2000 - 2024, Jelsoft Enterprises Ltd.
Content copyright ©2002 - 2020, Politics.be

